Jak działa Archivarix?
System Archivarix został zaprojektowany do pobierania i przywracania witryn, które nie są już dostępne z Archive.org oraz tych, które są obecnie online. Jest to główna różnica w stosunku do reszty „downloaderów” i „parserów witryn”. Celem Archivarix jest nie tylko pobranie, ale także przywrócenie strony internetowej w formie, która będzie dostępna na twoim serwerze.
Zacznijmy od modułu, który pobiera strony internetowe z archiwum internetowego. Są to serwery wirtualne zlokalizowane w Kalifornii. Ich lokalizację wybrano w taki sposób, aby uzyskać maksymalną możliwą prędkość połączenia z samym archiwum internetowym, ponieważ jego serwery znajdują się w San Francisco. Po wprowadzeniu danych w odpowiednim polu na stronie modułu https://pl.archivarix.com/restore/, wykonuje zrzut ekranu zarchiwizowanej witryny i zwraca się do interfejsu API Web Archive, aby poprosić o listę plików zawartych w określonym terminie odzyskiwania .
Po otrzymaniu odpowiedzi na żądanie system generuje komunikat z analizą odebranych danych. Użytkownik musi tylko nacisnąć przycisk potwierdzenia w otrzymanej wiadomości, aby rozpocząć pobieranie strony internetowej.
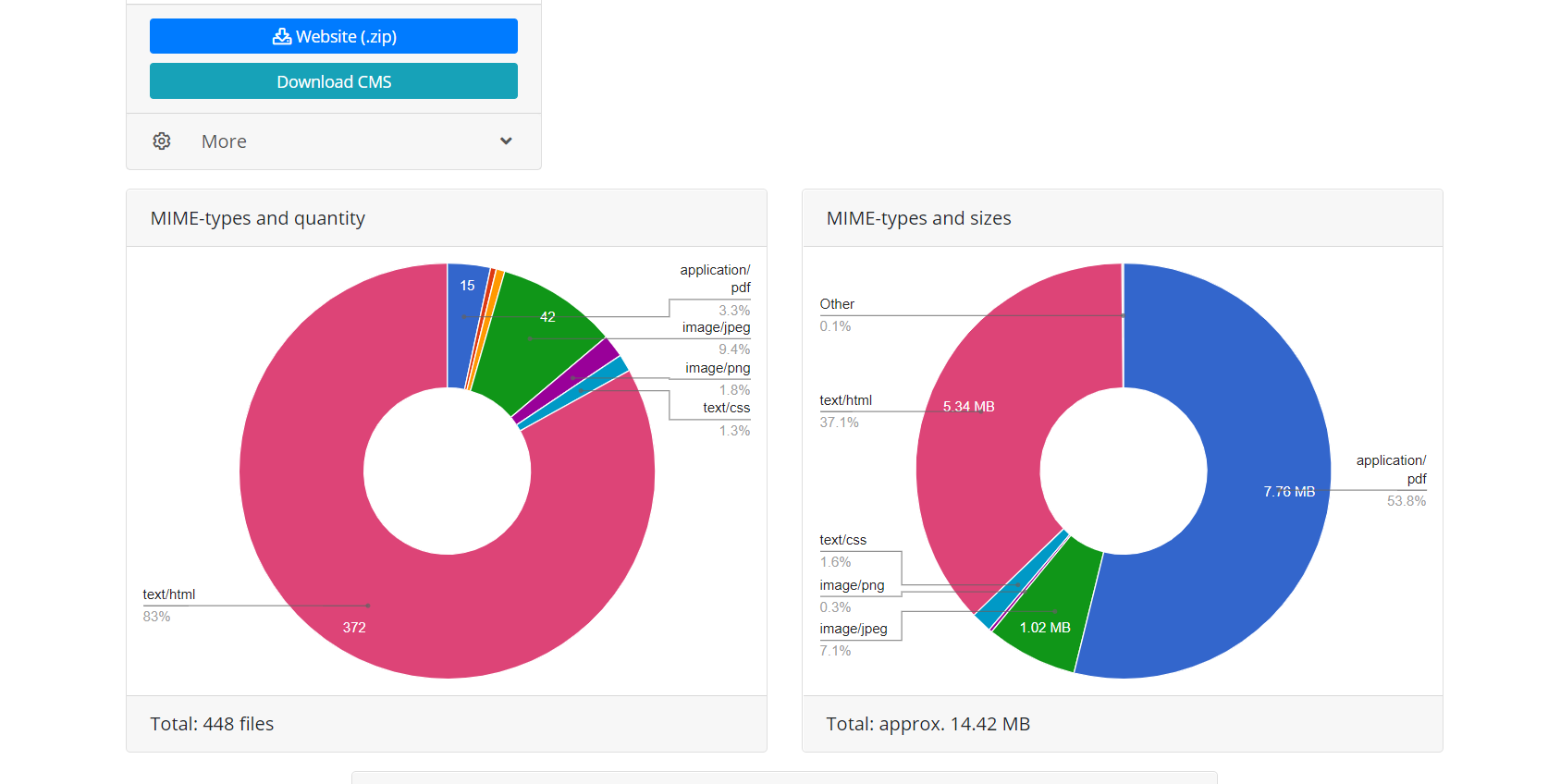
Korzystanie z interfejsu API Web Archive zapewnia dwie zalety w stosunku do bezpośredniego pobierania, gdy skrypt po prostu podąża za linkami witryny. Po pierwsze, wszystkie pliki tego odzyskiwania są natychmiast znane, możesz oszacować wielkość witryny i czas potrzebny do jej pobrania. Ze względu na charakter działania archiwum internetowego czasami działa on bardzo niestabilnie, dlatego możliwe jest zrywanie połączenia lub niekompletne pobieranie plików, dlatego algorytm modułu stale sprawdza integralność otrzymanych plików iw takich przypadkach próbuje pobrać zawartość, ponownie łącząc się z serwer archiwum internetowego. Po drugie, ze względu na specyfikę indeksowania stron internetowych przez Archiwum WWW, nie wszystkie pliki stron internetowych mogą mieć bezpośrednie linki, co oznacza, że gdy spróbujesz pobrać stronę internetową, po prostu podążając za linkami, będą one niedostępne. Dlatego przywracanie za pomocą interfejsu API archiwum internetowego używanego przez Archivarix umożliwia przywrócenie maksymalnej możliwej ilości zarchiwizowanej zawartości strony internetowej dla określonej daty.
Po zakończeniu operacji moduł pobierania z Archiwum internetowego przesyła dane do modułu przetwarzania. Z otrzymanych plików tworzy stronę internetową odpowiednią do instalacji na serwerze Apache lub Nginx. Witryna działa w oparciu o bazę danych SQLite, więc aby rozpocząć, wystarczy przesłać ją na serwer i nie jest wymagana instalacja dodatkowych modułów, baz danych MySQL i tworzenie użytkowników. Moduł przetwarzania optymalizuje utworzoną stronę internetową; obejmuje optymalizację obrazu, a także kompresję CSS i JS. Może to znacznie przyspieszyć pobieranie przywróconej witryny, w porównaniu do oryginalnej witryny. Szybkość pobierania niektórych niezoptymalizowanych stron Wordpress z wieloma wtyczkami i nieskompresowanymi plikami multimedialnymi może znacznie wzrosnąć po przetworzeniu przez ten moduł. Oczywiste jest, że jeśli strona została wstępnie zoptymalizowana, nie spowoduje to znacznego wzrostu prędkości pobierania.

Moduł przetwarzania usuwa reklamy, liczniki i analizy, sprawdzając otrzymane pliki w obszernej bazie danych dostawców reklam i analiz. Usuwanie zewnętrznych linków i klikalnych kontaktów odbywa się po prostu za pomocą kodu sumy kontrolnej. Ogólnie rzecz biorąc, ten algorytm wykonuje dość wydajne czyszczenie strony internetowej z „śladów poprzedniego właściciela”, chociaż czasami nie wyklucza to potrzeby ręcznej korekty. Na przykład samodzielnie napisany skrypt Java przekierowujący użytkownika witryny do określonej witryny generującej przychody nie zostanie usunięty przez algorytm. Czasami musisz dodać brakujące zdjęcia lub usunąć niepotrzebne pozostałości, jako spamowaną księgę gości. Dlatego konieczne jest zatrudnienie redaktora powstałej witryny. I już istnieje. Nazywa się Archivarix CMS.
Jest to prosty i kompaktowy CMS przeznaczony do edycji stron internetowych stworzonych przez system Archivarix. Umożliwia wyszukiwanie i zamianę kodu w całej witrynie przy użyciu wyrażeń regularnych, edycję treści w edytorze WYSIWYG, dodawanie nowych stron i plików. Archivarix CMS może być używany razem z dowolnym innym CMS na jednej stronie internetowej.
Porozmawiajmy teraz o innym module używanym do pobierania istniejących witryn. W przeciwieństwie do modułu do pobierania stron internetowych z Archiwum internetowego, nie można przewidzieć, ile i które pliki należy pobrać, więc serwery modułu działają w zupełnie inny sposób. Pająk serwera podąża za wszystkimi linkami, które są obecne na stronie, którą zamierzasz pobrać. Aby skrypt nie wpadał w niekończący się cykl pobierania dowolnej automatycznie generowanej strony, maksymalna głębokość łącza jest ograniczona do dziesięciu kliknięć. A maksymalna liczba plików, które można pobrać ze strony internetowej, musi zostać wcześniej określona.
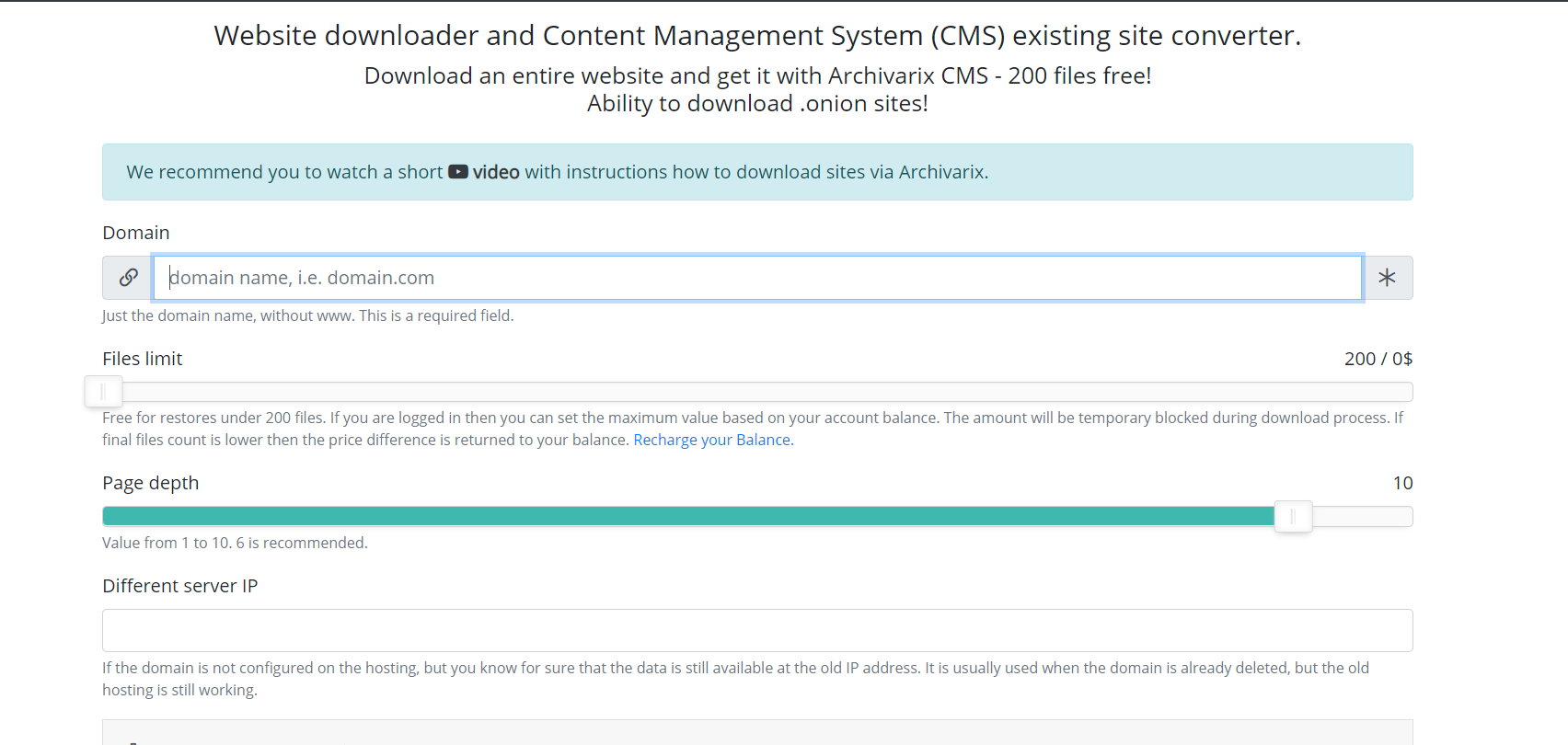
Aby uzyskać najbardziej kompletne pobieranie potrzebnej zawartości, w tym module wymyślono kilka funkcji. Możesz wybrać innego pająka usługi User-Agent, na przykład Chrome Desktop lub Googlebot. Polecający w celu obejścia maskowania - jeśli chcesz pobrać dokładnie to, co widzi użytkownik po zalogowaniu z wyszukiwania, możesz zainstalować Google, Yandex lub inną stronę polecającą. Aby zabezpieczyć się przed banowaniem przez IP, możesz pobrać stronę internetową za pomocą sieci Tor, podczas gdy IP pająka usługi zmienia się losowo w tej sieci. Inne parametry, takie jak optymalizacja obrazu, usuwanie reklam i analizy są podobne do parametrów modułu pobierania z Archiwum internetowego.
Po zakończeniu pobierania zawartość jest przenoszona do modułu przetwarzającego. Jego zasady działania są całkowicie podobne do działania ze stroną pobraną z wyżej opisanego archiwum internetowego.
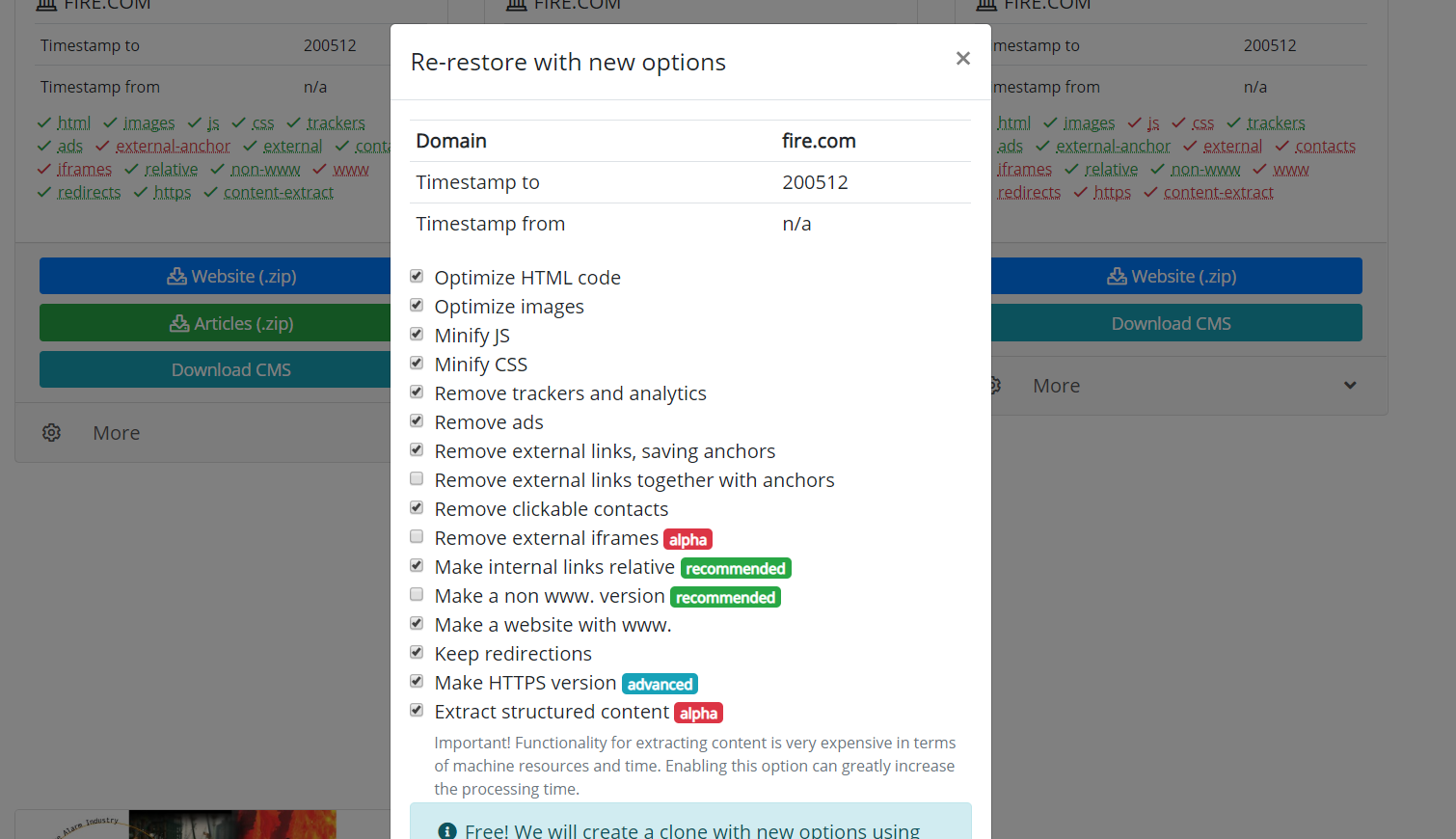
Warto również wspomnieć o możliwości klonowania przywróconych lub pobranych stron internetowych. Czasami zdarza się, że podczas odzyskiwania wybrano inne parametry, niż się okazało na końcu konieczne. Na przykład usunięcie linków zewnętrznych było niepotrzebne, a niektóre linki zewnętrzne były potrzebne, a następnie nie trzeba ponownie zaczynać pobierania. Musisz tylko ustawić nowe parametry na stronie odzyskiwania i rozpocząć ponowne tworzenie witryny.
Wykorzystanie materiałów artykułu jest dozwolone tylko wtedy, gdy opublikowany jest link do źródła: https://archivarix.com/pl/blog/how-does-it-works/

System Archivarix został zaprojektowany do pobierania i przywracania witryn, które nie są już dostępne z Archive.org oraz tych, które są obecnie online. Jest to główna różnica w stosunku do reszty „do…
Korzystając z opcji „Wyciąg z ustrukturyzowanej treści”, możesz łatwo utworzyć blog Wordpress zarówno ze strony znalezionej w archiwum internetowym, jak iz dowolnej innej witryny. Aby to zrobić, najpi…
Aby ułatwić edytowanie stron internetowych przywróconych w naszym systemie, opracowaliśmy prosty system plików Flat File CMS składający się tylko z jednego małego pliku php. Pomimo swoich rozmiarów, t…
W tym artykule opisano wyrażenia regularne używane do wyszukiwania i zastępowania treści na stronach internetowych przywróconych za pomocą systemu Archivarix. Nie są one unikalne dla tego systemu. Jeś…
- Pełna lokalizacja Archivarix CMS na 13 języków (angielski, hiszpański, włoski, niemiecki, francuski, portugalski, polski, turecki, japoński, chiński, rosyjski, ukraiński, białoruski).
- Eksportuj wszystkie aktualne dane witryny do archiwum zip, aby zapisać kopię zapasową lub przenieść do innej witryny.
- Pokaż i usuń uszkodzone archiwa zip w narzędziach do importu.
- Sprawdzanie wersji PHP podczas instalacji.
- Informacje dotyczące instalacji CMS na serwerze z NGINX PHP-FPM.
- W wyszukiwaniu, gdy włączony jest tryb ekspercki, wyświetlana jest data / godzina strony oraz link do jej kopii w archiwum internetowym.
- Ulepszenia interfejsu użytkownika.
- Optymalizacja kodu.
Jeśli jesteś native speakerem w języku, na który nasz CMS nie został jeszcze przetłumaczony, zapraszamy Cię do ulepszenia naszego produktu. Dzięki usłudze Crowdin możesz się zgłosić i zostać naszym oficjalnym tłumaczem na nowe języki.
- Obsługa interfejsu wiersza poleceń do wdrażania witryn internetowych bezpośrednio z wiersza poleceń, importu, ustawień, statystyk, historii czyszczenia i aktualizacji systemu.
- Obsługa zaszyfrowanych haseł password_hash (), których można używać w CLI.
- Tryb eksperta zawierający dodatkowe informacje debugowania, narzędzia eksperymentalne i bezpośrednie łącza do zapisanych migawek WebArchive.
- Narzędzia do uszkodzonych wewnętrznych obrazów i linków mogą teraz zwracać listę wszystkich brakujących adresów URL, zamiast je usuwać.
- Narzędzie importu pokazuje uszkodzone / niekompletne pliki zip, które można usunąć.
- Ulepszona obsługa plików cookie, aby spełnić wymagania nowoczesnych przeglądarek.
- Ustawienie domyślnego wyboru edytora dla stron HTML (edytor wizualny lub kod).
- Zakładka „Zmiany” pokazująca różnice w tekście, domyślnie wyłączona, może być włączona w ustawieniach.
- Możesz cofnąć się do określonej zmiany na karcie „Zmiany”.
- Naprawiono URL mapy witryny XML dla stron zbudowanych z subdomeną www.
- Naprawiono usuwanie plików tymczasowych, które zostały utworzone podczas instalacji / importu.
- Szybsze czyszczenie historii.
- Usunięto nieużywane frazy lokalizacyjne.
- Zmiana języka na ekranie logowania.
- Zaktualizowano pakiety zewnętrzne do najnowszych wersji.
- Zoptymalizowane wykorzystanie pamięci do obliczania różnic tekstowych na karcie Zmiany.
- Ulepszona obsługa starszych wersji rozszerzenia php-dom.
- Eksperymentalne narzędzie do naprawiania rozmiarów plików w bazie danych, jeśli edytowałeś pliki bezpośrednio na serwerze.
- Eksperymentalne i bardzo prymitywne narzędzie do eksportu płaskich konstrukcji.
- Eksperymentalna obsługa kluczy publicznych dla przyszłych funkcji API.
- Naprawiono: Sekcja Historia nie działała, jeśli rozszerzenie zip php nie było włączone.
- Karta Historia ze szczegółami zmian podczas edycji plików tekstowych.
- Narzędzie do edycji .htaccess.
- Możliwość czyszczenia kopii zapasowych do żądanego punktu wycofania.
- Blok „Brakujących adresów URL” został usunięty z Narzędzi, as jest dostępny z panelu głównego
- Dodano sprawdzanie i pokazywanie wolnego miejsca na dysku w panelu głównym.
- Poprawiona weryfikacja niezbędnych rozszerzeń PHP podczas uruchamiania i początkowej instalacji.
- Drobne zmiany kosmetyczne.
- Wszystkie narzędzia zewnętrzne zaktualizowane do najnowszych wersji.
- Oddzielne hasło dla trybu awaryjnego.
- Rozszerzony tryb bezpieczny. Teraz możesz tworzyć niestandardowe reguły i pliki, ale bez kodu wykonywalnego.
- Ponowna instalacja strony z CMS bez konieczności ręcznego usuwania czegokolwiek z serwera.
- Możliwość sortowania niestandardowych reguł.
- Ulepszone wyszukiwanie i zamiana dla bardzo dużych witryn.
- Dodatkowe ustawienia dla narzędzia „Metatag Viewport”.
- Wsparcie dla domen IDN na hostingu ze starą wersją ICU.
- W początkowej instalacji z hasłem dodano możliwość wylogowania.
- Jeśli .htaccess zostanie wykryty podczas integracji z WP, wówczas reguły Archivarix zostaną dodane na jego początku.
- Podczas pobierania stron według numeru seryjnego CDN służy do zwiększenia prędkości.
- Inne drobne ulepszenia i poprawki.
- Nowy pulpit do przeglądania statystyk, ustawień serwera i aktualizacji systemu.
- Możliwość tworzenia szablonów i wygodnego dodawania nowych stron do witryny.
- Integracja z Wordpress i Joomla za pomocą jednego kliknięcia.
- Teraz w Search-Substitution wykonuje się dodatkowe filtrowanie w postaci konstruktora, w którym można dodać dowolną liczbę reguł.
- Teraz możesz filtrować wyniki według domeny / poddomen, daty i godziny, rozmiaru pliku.
- Nowe narzędzie do resetowania pamięci podręcznej w Cloudlfare lub włączania / wyłączania trybu deweloperskiego.
- Nowe narzędzie do usuwania wersji w adresach URL, na przykład „?ver=1.2.3” w css lub js. Umożliwia naprawę nawet tych stron, które wyglądały krzywo w Archiwum Web ze względu na brak stylów w różnych wersjach.
- Narzędzie robots.txt ma możliwość natychmiastowego włączenia i dodania mapy mapy witryny.
- Automatyczne i ręczne tworzenie punktów wycofywania zmian.
- Import może importować szablony.
- Zapisywanie / importowanie ustawień modułu ładującego zawiera utworzone pliki niestandardowe.
- Dla wszystkich działań, które mogą trwać dłużej niż limit czasu, wyświetlany jest pasek postępu.
- Narzędzie do dodawania metatagu rzutni do wszystkich stron witryny.
- Narzędzia do usuwania uszkodzonych linków i obrazów mają możliwość rozliczania plików na serwerze.
- Nowe narzędzie do naprawy nieprawidłowych linków do kodu urlencode w kodzie HTML. Rzadko, ale może się przydać.
- Poprawione narzędzie brakujących adresów URL. Wraz z nowym modułem ładującym liczy teraz połączenia z nieistniejącymi adresami URL.
- Porady Regex w wyszukiwaniu i zamianie.
- Poprawione sprawdzanie brakujących rozszerzeń php.
- Zaktualizowano wszystkie używane narzędzia js do najnowszych wersji.
To i wiele innych kosmetycznych ulepszeń i optymalizacji prędkości.